Improving the Hacker News Ranking Algorithm - Part 2
Felix Dietze, Johannes NakayamaWe tried to make this article as accessible as possible. If you find any accessibility issues with this article, please let us know: mailto:mail@felx.me
Hacker News is a community with a general guideline to post “anything that gratifies one’s intellectual curiosity”. Content is curated by a news aggregator with a global frontpage. This has the effect that high-ranking content receives more attention.
As we understand it, the goal of the ranking algorithm is thus to distribute attention to submissions, such that submissions with higher quality receive more attention. We define quality of a submission as the fraction of all users, that, if exposed to the story, would upvote it. This means that quality is not an objective criterion, but collectively defined by the judgement of all community members.
In our previous article, we described two problems of the current Hacker News ranking algorithm.
- Upvotes and quality of a submission do not correlate well.
- High quality content gets overlooked.
We explained the underlying rich-get-richer dynamic by pointing out the following positive feedback loop:
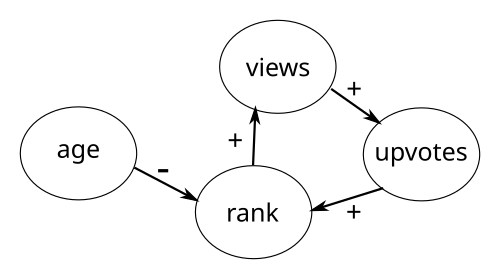
More exposure of a story leads to more views, which in turn leads to more upvotes, which leads to a higher rank on the frontpage, which in turn leads to even more views.
To alleviate this effect, we proposed that the positive feedback loop should be turned into a balanced feedback loop by introducing a view (click-through) penalty.
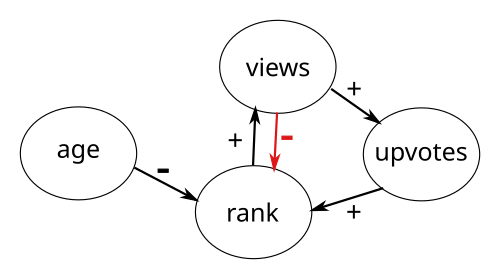
Our thought process was, that a post receiving many views and comparatively few upvotes is a good signal for low quality.
We submitted the article on Hacker News and received very helpful feedback.
Feedback Summary for our Proposal
Here we’ll address a few comments from the Hacker News comment thread:
Click-Throughs and False Positives
The author’s definition of “view” is “click-through”. Posts that are obviously not worth clicking through based on the title / domain will get no views, and thus keep getting seeded back into the rotation.
First of all, users pointed out that our definition of view was essentially equivalent to what’s called click-through in search engine terminology. Going forward, we will use the term click-through in place of our previously ill-defined notion of view. The problem with using click-throughs in the way we proposed though, is that it favors submissions that are obviously not worth clicking. These low-quality submissions will not accumulate click-throughs because their low quality is immediately apparent. Therefore the click-through penalty does not kick in as we intended with our proposed formula. Ironically, we might in fact have proposed a ranking formula that systematically produces false positives (high ranked low-quality content).
Click-Throughs Need User Tracking
Apart from not penalizing obvious low-quality submissions, users pointed out that the needed click-through data might not be available:
I guess I don’t entirely understand how this works - it sounds like you’re introducing a param you don’t actually have - you don’t know what the clickthroughs are, how they’re distributed, etc so this is entirely synthesized. Wouldn’t you be able to simulate your way to more or less anything this way? Seemingly worse for practical purposes, I don’t think this data actually exists - adding clickthrough tracking to HN would be a huge change to the privacy profile of the site.
Click-through is not currently available in the data that is provided by the Hacker News API, most likely because it is not tracked in the first place. One of the key features that users appreciate about Hacker News is the absence of client side tracking. If we used click-throughs in the ranking formula, they would have to be tracked on the client-side, which is undesirable. This feedback made it more obvious that our simplified simulations had to make strong assumptions about click-through behavior. And with these strong assumptions, the simulation would be prone to confirmation bias.
Nonetheless, we still think that a low ratio between upvotes and received user attention is a good signal for quality. Click-through is just not the right metric to measure user attention.
Sorting by ratio
An obligatory link to an article by Evan Miller about ranking: https://www.evanmiller.org/how-not-to-sort-by-average-rating.html However, to get the following requirement from the article:
The algorithm should not produce false negatives, the community should find all high-quality content.
it might be better to estimate the upper confidence bound, like in Upper Confidence Bound bandit, rather than the lower confidence bound.
This comment raises a very important point. We’re sorting the stories by a ratio upvotes / click-throughs and every story has a different amount of data.
How should we compare two stories, where one has 1 upvote / 2 click-throughs = 0.5 and another one 500 upvotes / 1000 click-throughs = 0.5?
The latter one obviously has more data and is therefore more accurate.
But how should we deal with cases where not much data is available?
Wilson Score Interval scores or Bayesian average are ways to deal with this problem.
At this point though, it is too early for us to address this problem.
We would like to figure out a good balancing feedback mechanism first and then apply these methods.
Definition of quality
What worries me is the definition of quality you use. We look for submissions that we find valuable for us, not necessarily high quality. Interests are varied, and we all get value from different things. Quality might be very correlated with value, but it’s not quite the same. And here comes the big issue: maybe more than 50% of the value we derive from HN comes from the comments. I feel many times we are upvoting submissions by sheer relevance, so we can have valuable discussions about a relevant topic. I don’t think the given metrics are capturing this. I like the analysis and the proposal, but it’s easy to see how there’s some very important perspective missing.
In our previous article, we didn’t provide a good definition of the term quality. So here is the one we’re working with:
The quality of a story is the fraction of users who would upvote a story, independent of their motive.
Note that this is not an objective measure of quality but a subjective one that depends on the taste of the community. We think that captures what the commenter meant by:
We look for submissions that we find valuable for us, …
Different voting weight on different ranks
Also, the ranking algorithm should take into account the rank of the content when the upvote happened - 10 upvotes for a content on the 5th page is much more impressive than 10 upvotes for a content on the 1st page (keeping everything else constant).
Implicitly, this was already part of our initial approach, as we assumed that the click-through distribution would decrease for lower ranks. Therefore stories on lower ranks get less negative feedback, which could be interpreted as votes having a higher weight.
But making the influence of different ranks explicit is a very good idea.
Upvote penalty in the original Hacker News Formula
We also noticed that we didn’t consider an intricacy of the original Hacker News formula in our initial argument:
upvotes has a 0.8 exponent.
$$ \text{rankingScore} = \frac{\text{upvotes}^{0.8}}{(\text{ageHours} + 2)^{1.8}} $$
Since $$\text{x}^{0.8}$$ grows slower than a linear function $$\text{x}$$, it acts as a limitation for too much user attention: The more upvotes a story already has, the less additional upvotes count for the score. It can also be seen as a negative feedback for high upvote counts.
This negative attention feedback via upvotes is no longer necessary for our approach. It is already provided by clickThroughs. So we can remove the 0.8 exponent in our new formula.
Revised Goals
Inspired from the feedback, we updated our goals as follows (added points are marked as bold green):
- The algorithm should not produce false negatives, the community should find all high-quality content.
- The algorithm should not produce false positives, obvious low-quality submissions should not get high rating
- Scores should correlate with quality so that submissions can be compared
- The quality of content on a future version of the front-page should be at least as high as on the current version of the front-page
- The user-interface should stay exactly the same
- The age penalty should behave the same way as it was designed
- Don’t introduce additional user tracking
- Bonus: A higher overall quality on the frontpage
- Bonus: Make it more difficult to game the system
- Bonus: Time of day and weekday should not influence the reach of high quality posts
Overall we’re very happy with the feedback we received from the Hacker News community. The weaknesses of our approach were pointed out very well. And that’s exactly what we needed to hear to improve our approach. Thank You!
New Idea: A different metric for user attention
We still believe that user attention as a negative feedback is a good way to balance the positive feedback loop.
But as we learned from the community, using clickThroughs is not sufficient, because it can produce false positives (low quality posts on high ranks). Besides, we don’t have access to that metric anyway.
That’s why we’ll look into another way to measure user attention.
To find a suitable metric, let’s first assess which data about user attention we actually have. From using the Hacker News API, we know that we can infer voting information of individual stories and we presume that HN probably only tracks pageviews.
We already know that stories on higher ranks get more attention because we know the distribution of average vote arrivals per rank.
![]()
Key Insight: Deriving Attention Metric from Vote Distribution
Since the distribution is calculated from many stories of different quality, we presume that attention follows roughly the same distribution.
Based on this insight, we’ll construct a new attention metric derived from the vote distribution.
We can observe the upvote arrivals for any rank at all points in time.
This means that we can infer a statistical process so that we can calculate how many votes we expect a story to get per time interval at any rank.
We call this expected_upvotes.
With this metric, we can compare how a story performed vs. how it should have performed on average.
We can view expected_upvotes as negative feedback.
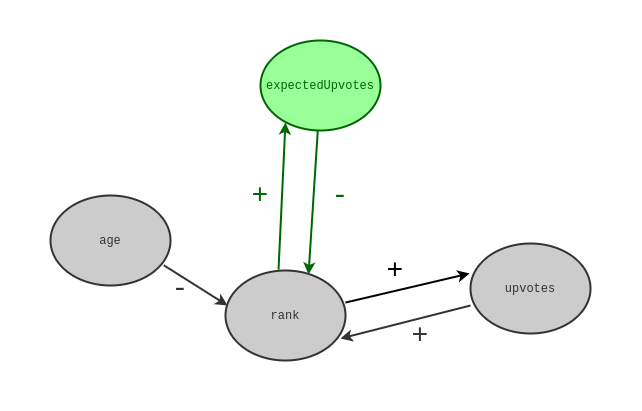
How to calculate expected upvotes
How can we calculate expected upvotes per rank?
With a time series of historical snapshots of the frontpage, we can calculate how many votes arrive on a specific rank over time.
Looking at a single rank and plotting the arrival distribution of ranks, we can see that it resembles a Poisson distribution.
And the expected value of a Poisson distribution equals its parameter lambda, which in turn can be estimated by averaging all samples.
This way we can calculate how many upvotes a story on a specific rank can expect.
With enough data, we can even calculate the expected upvotes for a specific rank at a specific time of day on a specific weekday.
![]()
Looking at the history of a single story over time, we can see that it was shown on a series of different ranks on the frontpage. And on every rank it is expected to collect a certain amount of upvotes. Summing up all these expectations over the lifetime of the story, we get a picture of how many upvotes the story was expected to receive and how many upvotes it actually received. Stories of higher quality will naturally over-perform and low quality stories will under-perform.
![]()
To summarize, our new idea is to use the cumulative expected votes per rank as a metric for user attention and use it as a negative feedback in the ranking formula.
This simple change has several advantages compared to our previous approach, which used clickThroughs as a negative feedback:
- No false positives possible (stories with low quality that are ranked high); e.g. stories that are obviously not worth clicking do not get negative feedback when using click-throughs. But using cumulative expected votes, they get penalized as intended.
- No positive feedback (upvotes) possible without negative feedback (expected_upvotes); e.g. if users only look at the comments and upvote, the expected upvotes at the current rank make sure that there is negative feedback for the respective user attention.
- Using expected upvotes does not require any additional user-tracking, it can be calculated from historical voting data
Constructing a new ranking algorithm
Compared to our previous formula, we remove the 0.8 exponent on upvotes and replace clickThroughs by cumulativeExpectedUpvotes. A new formula could look like this:
$$ \text{rankingScore} = \frac{\text{upvotes}}{\text{cumulativeExpectedUpvotes} \ast (\text{ageHours} + 2)^{1.8}} $$
upvotes includes the submitter’s vote, so it starts at 1.
cumulativeExpectedUpvotes also starts at 1 as the submitter’s vote is always expected.
Like in our last proposal, we still think that the same formula should be applied on the new- and the front-page with the caveat that new and frontpage should be mutually exclusive. There would be an upvote threshold between new and frontpage which decides where a story is shown (e.g. 4 upvotes). This means that the expected votes estimation needs to take into account on which site (new or front) the upvote occurred, i.e. on which site the story is at the moment the upvote occurred.
A possible implementation of this formula within Hacker News is given by the following algorithm:
= 4 # to be discussed
= 1500 # as on HN right now
= 15 # as on HN right now
= f
= f
# apply ranking formula for every story
=
/
/ ^1.8
# sort stories by ranking score
=
# increase cumulative expected upvotes for every story
= + 1
+=
return
# Repeat every {interval_seconds}:
# Calculate the new- and frontpage
# and update the cache to serve them
=
=
In the code, expected_upvotes is parameterized over rank, day_of_week and time_of_day because we observed a periodic effect over week day and time of day.
We will discuss this below.
Discussion
We addressed many shortcomings of our previous approach, but we still consider it a work in progress. In this section, we aim to scrutinize our approach as thoroughly as possible and discuss some open questions.
If you find flaws in our proposal that we overlooked and didn’t mention in this section, please let us know!
Expected Upvotes Depends on Time of Day and Day of Week
We touched on the possibility that expected_upvotes might be computed from historical data, but there are many non-trivial things to consider.
Most importantly, we have to address the issue posed by variation in the vote arrival rates due to time of day and day of the week.
In the data we collected, we can clearly observe patterns that arise with regard to these time factors.
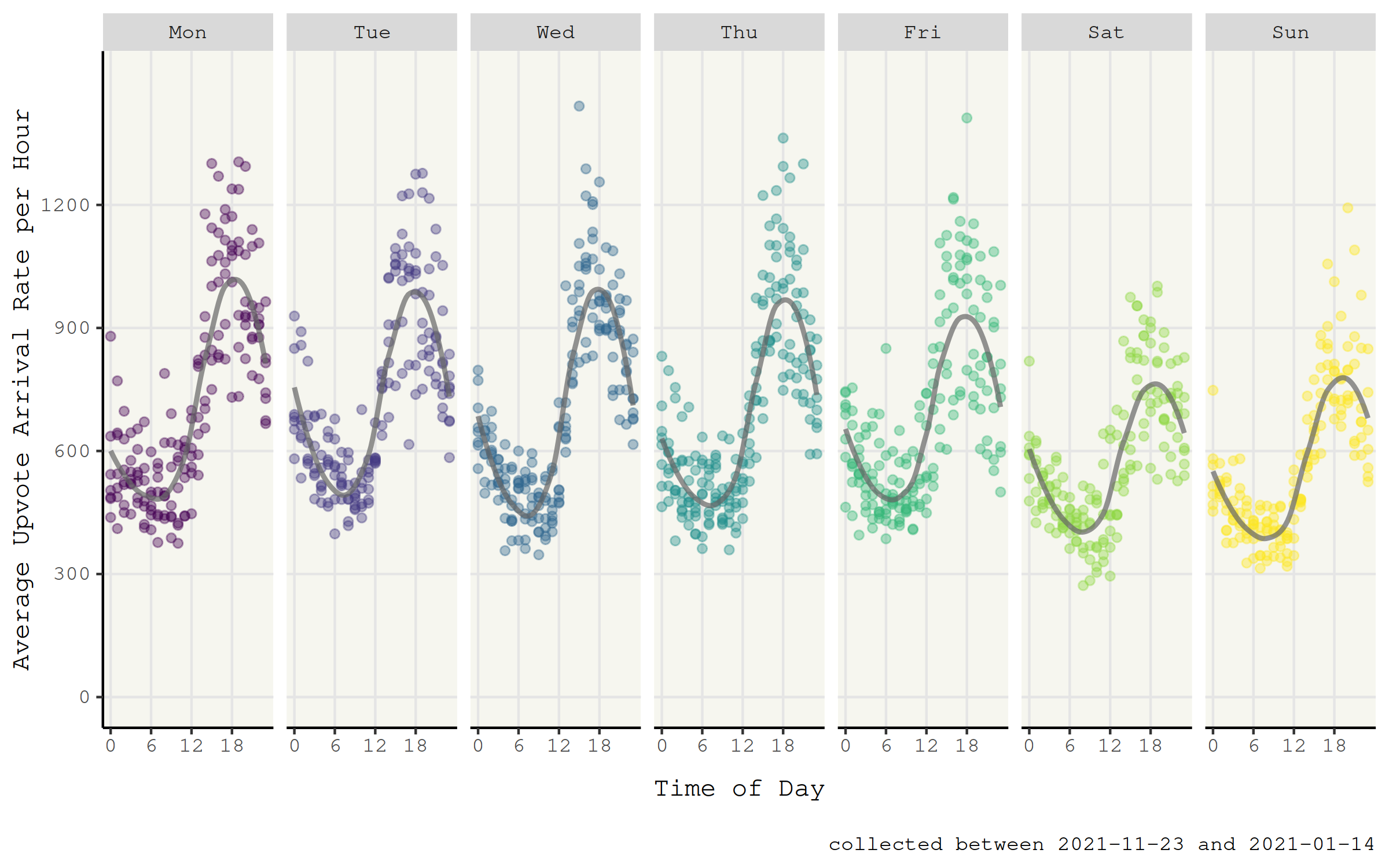
If we simply computed expected_upvotes from the rank (thus averaging over all data points regardless of arrival time), we might systematically put stories that are posted on certain times at an advantage.
One way to circumvent this problem would be to compute expected_upvotes only from data points that were sampled in a specified time window.
For example, we could use data points from the previous month that were sampled in that hour of day on that day of the week.
This way, we would take the effect of timing into account.
Nonetheless, we want to explore the severity of this problem in simulations in the future.
Changes in Activity Patterns over Time
The periodicity of the activity on the site suggests that a large portion of the user base is located in a similar time zone. Another observation was that the number of total upvotes on hacker news seems quite stable in the recent years.
However, the user base can change.
Maybe in the future, large numbers of users from other parts of the world start to use the site or the community is growing or shrinking.
Such changes would bias the rankingScore. But we believe that these changes happen slowly enough to not cause any problems, when the calculation of expected_upvotes uses recent historical data.
How do we Calculate Expected Upvotes for very Low Ranks?
As we calculate expected upvotes for all 1500 newest stories, we need to calculate them for every rank between 1 and 1500. But the very low ranks have don not accumulate enough upvotes to estimate expected upvotes. So some extrapolation is necessary.
Cumulative Expected Votes Only Works because we Use the Arithmetic Mean
In our approach described above, we collect information by simply adding it to the expected vote count (cumulation).
But this has the implicit assumption that the arithmetic mean is a good estimator for expected votes.
It would be more precise to sample a ratio of upvotes / expected_upvotes at a specified time unit.
So why don’t we do that?
Sampling at a very high rate (15 seconds in our proposal), a large portion of the samples would be 0 / expected_upvotes = 0.
On the other hand, there would be rare samples of 1 / expected_upvotes or 2 / expected_upvotes >> 0 which would then correct the score upwards.
Threshold between New and Front page
We proposed to use our algorithm for the front- and the new-page. Where both pages are mutually exclusive. Therefore we need to decide a condition where a specific story should be shown. The current Hacker News site has a threshold of 3 upvotes as a necessary criterium for a story to be shown on the frontpage. This is an arbitrary decision to control the quality level of the frontpage. With our threshold we need to do the same thing. But it’s up for debate what a sensible threshold should be. We need to figure this out with real-life experiments in the future.
Conclusion and Future Work
In this post, we addressed the most important feedback that we received for our previous proposal on how to improve the Hacker News ranking formula. Most importantly, we abandoned click-through as a metric for user attention. Instead, we measure attention with expected upvotes and move to a formula that estimates quality as the ratio of upvotes to expected upvotes. We also identified several factors that need to be taken into account when estimating expected upvotes.
Still, there are many open questions. For once, we layed out that sorting by ratio might have issues. It doesn’t take into account that not all ratios contain the same amount of information. A story that has just been posted might get a few upvotes very early on purely by chance. The next step for us is going to be to figure out, how uncertainty about the ratio could factor into the ranking.
Furthermore, while we sketched out how expected upvotes might be estimated, we still need to develop an actual model for this metric. From the data we collected so far, it seems like a pretty straight forward Poisson model might be sufficient, but we have to verify this by putting it to a test. For this purpose, we will do simulations and see whether the proposed formula and algorithm are feasible.
Once again, we would like to thank everyone who has provided us with valuable feedback, on Hacker News as well as in our feedback cycles.
Thanks for reading. We appreciate any feedback and ideas. We’re also looking for ways to fund our research. Please get in touch!